Memory絡みで書いてきたので、基礎的な部分をおさらいしておきます。
プログラムで使用できるメモリには、ヒープとスタックがあります。 他にもありますが、今回はこの2つの違いについて書いてみます。 (他にも詳細に説明しているページはあるので、より厳密に知りたい方は「検索」しましょう)
スタック
ローカル変数や関数の引数などが格納されます。 FILO / LIFO式のデータ構造になっています。 よく、スタックに積むという言い方をしますが、これはデータ構造を表した言い方です。 使用きる領域は、ヒープと比べるとかなり小さいです。 関数の再帰呼び出しでは、スタックの消費が大きいので stack overflow になりやすいです。 積んだデータを順番(逆順)に取り出すので、構造的にはメモリの断片化は発生しません。 データの格納順と取り出し順は、全く逆になるので、それを人が理解するのは困難ですが、 プログラム(コンピュータ)からは、シンプルな構造です。 データの管理領域なども不要(最後に積んだ位置だけがわかればいい)です。 ページ記述言語として有名なPostScriptはスタック型を採用しています。
ヒープ
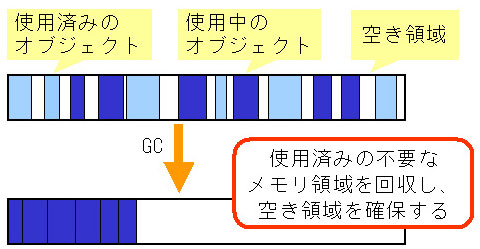
プログラムから「メモリを確保する」というとヒープに必要なメモリブロックを確保することをさします。 ヒープで使用可能なメモリ領域は非常に大きいです。 32bitOS上のプログラムの場合で2GB程度、64bitOSの場合はそれ以上。 64bitOSの場合、アドレス空間としては16EBまで表現できますが実際にはそんなにメモリを確保できません。 配列や、画像など使用されることも多いです。 ヒープの中に必要な分の空きがあれば、メモリを確保できます。 メモリの確保・解放が繰り返されるうちにメモリの断片化が発生することがあります。 例)(図とは一致していません) 500bytes確保・・・・(1) 100bytes確保・・・・(2) 300bytes確保・・・・(3) (2)の領域を解放・・・(4) この時点で(1)と(3)の間に100bytesの空き領域ができる 200bytes確保・・・・(5) 間の100bytesでは足りないので空いている領域に確保される のようなシーケンスで断片化が発生し、使用可能領域が減っていきます。 ヒープでは、確保したメモリ以外に管理領域(メモリのどこが使用されているかを管理する)が必要になります。 プログラムからは、一般的にポインタと呼ばれるアドレス値を使ってアクセスされます。 断片化しやすい構造なので、多くのプログラム言語に置いてGCと呼ばれる断片化を減らす仕組みが組み込まれています。 画像のプログラムA,B,Cは、関数A,B,Cと読み替えてください。

GC(ガベージコレクション)
ヒープの断片化を緩和する機構です。 多くのプログラム言語に実装されています。 C言語など、直接メモリを利用できる言語ではメモリ管理をプログラマ自身が行う必要があります。 (ライブラリなどで、それを補完するものもあります) GCでは、ヒープに確保されたメモリから利用(参照)されていないメモリ領域を走査し、 利用しているメモリ領域の隙間を埋めます。 Javaでは、確保メモリに対して参照フラグを用意しており、このフラグがOffになっているものが対象になります。 一般に、プログラムが利用するポインタは直接確保されたメモリを差さないようになっています。 プログラムが利用するポインタ(1)は言語で用意したポインタ(2)を差し、(2)のポインタがメモリ領域を差すようにすることで、 GC処理では、(1)のポインタ値は変わらず(2)のポインタ値を新しいアドレスに変更することで実装されることが多いです。 1度のGC処理では、断片化の緩和が不十分な場合、GCは繰り返し実行される実装が多いです。
まとめたつもりが散文になってしまった。
このブログ、フォントがあれで読みづらい。 サンセリフの読みやすいフォント希望。
